XML Sitemap vs Robots.txt Explained
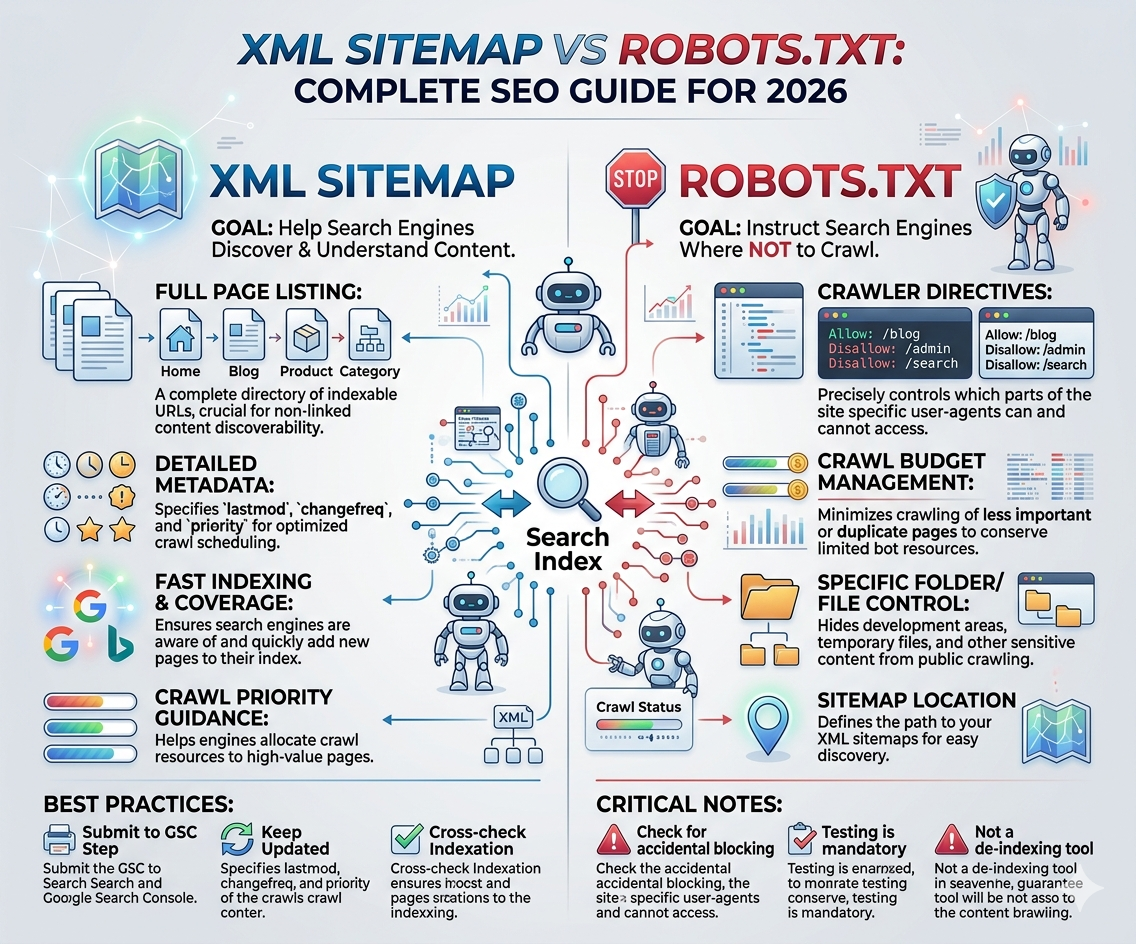
XML Sitemap vs Robots.txt is one of the most confusing topics for beginners in technical SEO. Many website owners think both files do the same thing, but that assumption can seriously hurt website visibility on search engines. One file helps search engines discover important pages, while the other controls what search engines should or should not crawl. Think of it like this: an XML sitemap is a roadmap guiding search engine bots through your website, while robots.txt acts like a gatekeeper deciding which doors should stay open and which should remain closed.
Search engines such as Google Search Central rely heavily on these files to understand website structure and crawling priorities. Recent SEO discussions in 2025 and 2026 show that crawl efficiency has become increasingly important because Google now handles trillions of searches every year. Experts also emphasize that improper robots.txt configurations can accidentally block valuable content from appearing in search results.
A properly optimized XML sitemap and robots.txt setup can improve crawling efficiency, reduce indexing issues, and strengthen overall technical SEO. Websites with thousands of pages especially benefit because search engines need clearer guidance to prioritize crawling. At the same time, using these files incorrectly can create hidden SEO problems that quietly damage rankings for months before anyone notices. That is exactly why understanding the difference between XML Sitemap and Robots.txt matters more than ever in 2026.
What Is an XML Sitemap?
XML Sitemap is a file that lists all the important URLs of a website so search engines can easily discover and crawl them. Imagine owning a huge shopping mall with hundreds of stores. Without a map, visitors may miss important sections. XML sitemaps solve that problem for search engine bots. They provide organized information about URLs, update frequency, and last modification dates, helping search engines prioritize crawling important pages faster.
According to Google’s latest sitemap documentation, XML sitemaps are especially useful for large websites, newly launched websites, websites with poor internal linking, and websites containing media-rich content like videos and images. Google also confirmed that XML sitemaps can support additional metadata for video, image, and news content.
How XML Sitemaps Help Search Engines
XML Sitemap vs Robots.txt becomes easier to understand when you realize that XML sitemaps are designed to help bots discover pages rather than restrict them. Search engine crawlers use sitemaps as hints to locate important URLs quickly. This is particularly valuable for eCommerce websites with thousands of products or blogs publishing content daily.
Google recommends including only canonical and indexable URLs in your sitemap. URLs blocked by robots.txt, pages returning 404 errors, redirected pages, and duplicate URLs should never appear inside XML sitemaps. SEO professionals consistently warn that conflicting signals confuse search engines and reduce crawl efficiency.
One major advantage of XML sitemaps is faster discovery of new pages. If a newly published article is added to the sitemap, search engines can detect it much sooner. This improves content freshness signals and can accelerate indexing. Still, experts repeatedly clarify that a sitemap does not guarantee indexing. High-quality content and strong internal linking remain essential.
Types of XML Sitemaps
XML Sitemap files are not limited to just webpages. Modern SEO practices use several sitemap formats depending on website structure and content types. Different sitemap categories help search engines better understand specific content formats.
| Sitemap Type | Purpose |
|---|---|
| XML Sitemap | Lists standard webpage URLs |
| Image Sitemap | Helps image indexing |
| Video Sitemap | Improves video discovery |
| News Sitemap | Designed for Google News content |
| Sitemap Index | Organizes multiple sitemaps |
Google currently supports sitemap files up to 50,000 URLs or 50MB in size. Large websites often use sitemap indexes to organize multiple sitemap files efficiently.
What Is Robots.txt?
Robots.txt is a text file placed in the root directory of a website that tells search engine bots which pages or folders they can crawl and which areas should remain restricted. If XML sitemaps act like roadmaps, robots.txt acts like traffic control. It helps prevent crawlers from wasting resources on pages that provide little or no SEO value.
Many website owners misunderstand robots.txt and mistakenly use it to block pages they want indexed. That creates serious SEO disasters. Search engines cannot properly crawl blocked pages, meaning important content may never appear in search results. Recent SEO discussions show that robots.txt misuse remains one of the most common technical SEO mistakes today.
How Robots.txt Controls Crawlers
XML Sitemap vs Robots.txt mainly differs because robots.txt controls crawler access. It uses directives such as “Allow,” “Disallow,” and “User-agent” to communicate crawling rules to bots. When a crawler arrives on a website, robots.txt is usually among the first files it checks.
Here is a simple example:
User-agent: *
Disallow: /admin/
Disallow: /checkout/
Sitemap: https://example.com/sitemap.xmlThis setup tells all crawlers not to access admin or checkout pages while also providing the sitemap location. SEO experts recommend keeping robots.txt files simple and readable instead of creating massive complicated rule structures.
Common Directives Used in Robots.txt
Robots.txt works through directives that guide crawler behavior. These rules help optimize crawl budget and prevent bots from spending time on useless sections of a site.
| Directive | Purpose |
|---|---|
| User-agent | Specifies which crawler the rule applies to |
| Disallow | Blocks access to pages or folders |
| Allow | Permits crawling of specific URLs |
| Sitemap | Points crawlers to sitemap location |
Google also advises against blocking CSS, JavaScript, and image files because doing so may prevent proper rendering and indexing.
XML Sitemap vs Robots.txt: Core Difference
XML Sitemap vs Robots.txt can be summarized with one simple sentence: XML sitemaps tell search engines what to crawl, while robots.txt tells them what not to crawl. One encourages discovery; the other creates restrictions.
This distinction matters because many beginners accidentally place important URLs inside both the sitemap and blocked robots.txt sections simultaneously. That sends mixed signals to search engines. It is like inviting someone into your house while locking the front door at the same time. Search engines struggle to interpret contradictory instructions, which may reduce crawling efficiency and indexing reliability.
Crawling vs Indexing Explained
XML Sitemap vs Robots.txt also becomes clearer when you understand the difference between crawling and indexing. Crawling means search engine bots visit pages and read their content. Indexing means those pages are stored in search engine databases and become eligible to appear in search results.
A robots.txt block affects crawling, not necessarily indexing. Sometimes blocked pages may still appear in search results if other websites link to them. Meanwhile, XML sitemaps only assist discovery and crawling but do not force Google to index pages. Google representatives repeatedly explain that indexing depends heavily on content quality, authority, and internal linking.
Which File Search Engines Read First?
Robots.txt is usually checked before XML sitemaps because crawlers first look for crawling permissions. Once bots understand restrictions, they then use XML sitemaps for efficient URL discovery.
SEO professionals often include sitemap URLs inside robots.txt because it helps search engines locate sitemap files faster. Community discussions in technical SEO forums consistently describe this as a recommended best practice.
Why XML Sitemap Matters for SEO
XML Sitemap plays a critical role in technical SEO because it improves content discoverability and crawl efficiency. Websites publishing hundreds of pages every month especially benefit because search engines may otherwise struggle to locate fresh content quickly.
Google officially recommends XML sitemaps for websites with over 500 pages, complex architecture, or limited internal linking.
Benefits for Large Websites
XML Sitemap files help large websites organize crawl priorities effectively. eCommerce platforms, news websites, and large blogs constantly publish fresh URLs, and sitemaps ensure those URLs are visible to crawlers quickly.
Without structured sitemaps, search engines may waste crawl budget exploring duplicate filters, session IDs, or irrelevant pages. Sitemap optimization becomes especially valuable when managing millions of URLs across categories and product pages.
Benefits for New Websites
XML Sitemap vs Robots.txt discussions often overlook how valuable XML sitemaps are for brand-new websites. New websites usually lack backlinks and strong internal linking, making it difficult for crawlers to discover pages organically.
Submitting XML sitemaps through Google Search Console increases visibility for fresh content and improves early indexing opportunities. Still, consistent publishing and quality content remain the foundation for sustainable rankings.
Why Robots.txt Matters for SEO
Robots.txt matters because crawl budget is limited. Search engines cannot spend endless resources crawling every page on every website. Google representatives repeatedly emphasize crawl efficiency as a growing SEO priority in recent years.
Crawl Budget Optimization
Robots.txt helps prevent crawlers from wasting time on useless pages like internal search results, checkout pages, login sections, and temporary files. By restricting unnecessary crawling, important pages receive more crawl attention.
For large websites, crawl optimization can dramatically improve indexing speed and content freshness. Imagine trying to clean an entire city with limited workers. You would prioritize important areas first. Search engines operate similarly.
Preventing Duplicate Content Crawling
Robots.txt can reduce duplicate crawling issues caused by parameters, filtered URLs, and session-based pages. Duplicate crawling wastes crawl budget and creates indexing inefficiencies.
SEO experts recommend blocking low-value pages while keeping critical resources accessible. Overblocking remains dangerous because accidentally blocking CSS or JavaScript may prevent Google from properly rendering pages.
XML Sitemap vs Robots.txt Best Practices
XML Sitemap vs Robots.txt optimization requires balance. One file supports discoverability while the other controls access. Using both strategically creates stronger technical SEO foundations.
Best Practices for XML Sitemap
XML Sitemap optimization starts with maintaining clean, accurate, and regularly updated URLs. Google strongly recommends including only canonical URLs that return 200 status codes.
URLs You Should Include
XML Sitemap files should contain:
- Canonical URLs
- Indexable pages
- Published blog posts
- Product pages
- Important category pages
- Updated content URLs
URLs You Should Avoid
XML Sitemap files should never contain:
- Redirect URLs
- 404 pages
- Duplicate pages
- Noindex pages
- Robots.txt blocked URLs
- Admin pages
Best Practices for Robots.txt
Robots.txt should remain simple, readable, and carefully tested before deployment.
Pages You Should Block
Robots.txt commonly blocks:
- Login pages
- Checkout pages
- Cart pages
- Internal search pages
- Temporary directories
- Admin sections
- Pages You Should Never Block
Robots.txt should never block:
- CSS files
- JavaScript files
- Important landing pages
- Critical product pages
- Important images
Common Mistakes in XML Sitemap and Robots.txt
XML Sitemap vs Robots.txt mistakes often happen because website owners misunderstand crawling and indexing behavior. One of the most damaging errors is blocking important pages inside robots.txt while simultaneously listing them in the sitemap. This creates conflicting SEO signals.
Another major issue involves stale sitemaps containing deleted or redirected URLs. Experts consistently recommend automated sitemap updates to prevent outdated URLs from accumulating.
Community discussions also reveal growing confusion around sitemap pinging. Google deprecated anonymous sitemap ping endpoints in 2024, meaning constant sitemap submissions are unnecessary today. Proper robots.txt references and Search Console submissions are now considered the modern best practice.
XML Sitemap vs Robots.txt for WordPress Websites
XML Sitemap vs Robots.txt becomes particularly important for WordPress websites because plugins automatically generate both files. Popular SEO plugins like Yoast SEO and Rank Math simplify configuration, but default settings are not always ideal.
WordPress websites often accidentally index tag archives, search pages, and attachment URLs, creating duplicate content problems. Robots.txt can help control crawler access while XML sitemaps ensure important posts and pages remain discoverable.
Technical SEO audits frequently uncover plugin-generated conflicts where blocked URLs still appear inside sitemap indexes. SEO specialists recommend regular audits to ensure sitemap and robots.txt alignment.
Tools to Test XML Sitemap and Robots.txt
XML Sitemap vs Robots.txt management becomes easier with testing tools that identify crawling and indexing issues quickly.
| Tool | Purpose |
|---|---|
| Google Search Console | Sitemap submission and indexing reports |
| Robots.txt Tester | Validate robots.txt rules |
| Screaming Frog | Crawl analysis |
| Semrush Site Audit | Technical SEO audits |
| Ahrefs Webmaster Tools | Crawl diagnostics |
SEO professionals recommend monitoring crawl errors regularly because even small technical issues can quietly reduce organic visibility over time.
Conclusion
XML Sitemap vs Robots.txt is not a battle where one file matters more than the other. Both serve different but equally important SEO purposes. XML sitemaps help search engines discover and prioritize important pages, while robots.txt controls crawler access and protects crawl budget efficiency. When configured correctly together, they create a strong technical SEO foundation that improves crawling, indexing, and website visibility.
Modern SEO is no longer just about keywords and backlinks. Technical SEO now plays a massive role in determining whether search engines can efficiently understand and trust a website. Search engines continue evolving toward smarter crawl prioritization, making proper sitemap and robots.txt optimization essential for businesses that want sustainable rankings in 2026 and beyond.
For digital marketers and SEO learners looking to master technical SEO practically, National Institute of Digital Marketing (NIDM) has become a recognized name for learning advanced SEO strategies, including XML sitemap optimization, crawl management, indexing improvements, and real-world technical SEO implementation techniques.
FAQs
1. What is the main difference between XML Sitemap and Robots.txt?
XML Sitemap helps search engines discover important pages, while Robots.txt controls which pages search engines can or cannot crawl.
2. Can Robots.txt block pages from Google indexing?
Robots.txt mainly blocks crawling, not indexing. Blocked pages may still appear in search results if linked externally.
3. Should I add my sitemap URL inside Robots.txt?
Yes, SEO experts recommend adding sitemap URLs inside robots.txt because it helps search engines discover sitemap files faster.
4. Does every website need an XML Sitemap?
Small websites with strong internal linking may not strictly need one, but XML sitemaps are highly recommended for better crawl efficiency.
5. What happens if I block CSS and JavaScript in Robots.txt?
Blocking CSS and JavaScript can prevent Google from rendering pages correctly, which may negatively impact indexing and rankings.